Serverless processing of security logs using DuckDB and delta-rs
This post was adapted from work performed by the research and development team in DNB’s Cyber Defense Center. The original motivation was to investigate building a simple event-driven ingestion pipeline using serverless technology to process JSON data and insert it into Delta tables using delta-rs. However, Microsoft’s append blob format introduced complexities that required a different approach.
We dramatically reduced both operational cost and complexity of our ingestion systems - cutting costs by 90% with a simple serverless pipeline built on Microsoft Defender for XDR, Azure append blobs, Delta Lake, and DuckDB:
Monthly cost
Infrastructure cost comparison between the two processing approaches.
Delta Tables, Security Logs, and ELT
Delta tables have been used for security log storage for a long time. In fact, when Delta Lake was introduced at the 2018 Spark+AI summit, the first featured use case was Apple’s threat detection and response platform. Their architecture was built around a design where logs where written to S3, and then Spark structured streaming jobs were used with the s3-sqs source to process new files as they arrived.
While Apple demonstrated how Delta tables can handle petabytes of security logs at scale, the fundamental challenge remains the same for any organization: how do you cost-effectively get logs into Delta tables in the first place?
Building an Efficient Ingestion Pipeline
We will explore how to ingest security logs cost-effectively by moving away from Apache Spark and the JVM, and instead building a serverless architecture that uses very efficient C++ and Rust libraries.
Let us first look at the general architecture of a security log ingestion pipeline.
Fig 1: A high-level security logs Delta lake ingestion pipeline.
To summarize the information in the above diagram, what we need is to create an efficient architecture to:
- Read JSON from object storage or some other source and apply the proper schema.
- Perform some minor transformations and add some metadata columns.
- Append the data into a Delta table.
- Implement some mechanism that handles corrupt records.
Before diving into each component we will introduce the data source - Microsoft Defender for XDR, and explain the challenges it presents for efficient ingestion. We will then examine our current architecture and identify the key issues that drive the need for a more cost-effective approach.
Microsoft Defender for XDR
Microsoft Defender for XDR provides security telemetry across endpoints, email, identities, cloud applications, infrastructure, and vulnerability management.
Microsoft offers two export options:
Event Hubs and Delta Live Tables
We initially used Event Hub export with Delta Live Tables (DLT). While operationally reliable, Microsoft’s event hub format creates processing complexity that drives up costs.
Microsoft exports security logs using this JSON structure:
{
"records": [
{
"time": "<The time WDATP received the event>"
"tenantId": "<tenantId>",
"category": "<AdvancedHunting-category>",
"properties": {
<WDATP Advanced Hunting event as Json>
}
}
]
}The schema of the JSON payload when Defender for XDR logs are streamed to an event hub.
Processing this structure requires:
- Exploding the
recordsarray into individual rows - Partial deserialization to extract
categoryandtimestamp(since thepropertiesschema depends oncategory) - Writing to a bronze-layer table partitioned by
categoryandtimestamp - Separate processing streams for each category that apply appropriate schemas and write to silver tables
Fig 2: A continuously streaming DLT pipeline for processing Defender for XDR data from an event hub.
While this DLT pipeline provides excellent autoscaling and stability, its distributed nature introduces overhead for our straightforward append-only workload.
Beyond the JVM
This led us to explore alternatives that could eliminate the JVM overhead entirely. We needed a solution that could handle our simple append-only workload without the complexity of a distributed processing framework.
The Scribd team had already solved a similar problem using delta-rs and Delta Lake’s transaction identifier system. We realized we could adapt their approach - using transaction identifiers to track processing state - to eliminate both the JVM overhead and the need for external coordination systems.
Kafka Delta Ingest
In 2021, engineers at Scribd - Christian Williams, QP Hou, and R. Tyler Croy - faced the same problem. They needed a way to stream data into Delta Lake from Kafka efficiently, cheaply, and at scale. Earlier they had created a native-rust binary for Delta Lake - delta-rs. They realized they could use this library to create a daemon service kafka-delta-ingest for writing the contents of a topic into table.
The design document explains in-detail how KDI works, but the main points are summarized as follows:
-
A job is a group of processes that are responsible for reading messages from one Kafka topic and writing it to a single table. Partitions of that topic are distributed amongst the processes through Kafka’s consumer group mechanism.
-
In order to avoid the small file problem and be more efficient, Kafka Delta ingest buffers the transformed data in memory before writing the Parquet files directly to object storage. The actual object storage write occurs when the memory buffer either exceeds a configured size threshold or after specified max duration has passed.
-
Transformations are expressed using JMESPath queries and are typically used to extract partition columns or include other metadata.
-
When a process eventually performs the append operation, it commits the offset of the associated partition in a transaction identifier. At startup or after a Kafka rebalance a process can query the delta log to find the last processed offset for each partition it is assigned.
The final point is worth highlighting as it is this mechanism that eliminates the need for processes to talk to each other. By storing offsets in the Delta table itself, each process works independently. This approach turns what would typically need a complex distributed system into something much simpler - just separate processes that can easily scale up. There is no external database needed to track state - everything lives in the Delta log.
Transaction Identifiers
To better understand how this works in practice, let us walk through a concrete example. Imagine we have a Kafka topic containing process creation events that we want to stream into a ProcessEvents Delta table.
The key innovation that makes this architecture work is Delta Lake’s transaction identifier system. As the official documentation explains:
Transaction identifiers are stored in the form of appId version pairs, where appId is a unique identifier for the process that is modifying the table and version is an indication of how much progress has been made by that application. The atomic recording of this information along with modifications to the table enables these external system to make their writes into a Delta table idempotent.
Delta Protocol documentation
In practice, this means each transaction stores two additional pieces of information:
{
appId: "kafka topic identifier",
version: "last offset processed"
}For our streaming use case, the appId identifies the specific Kafka topic, while the version tracks the last processed offset from that topic.
This design allows the process to resume exactly where it left off after a restart or failure.
The diagram below illustrates how this works across multiple append operations:
Fig 3: An example of how to use the Delta Python API to create a table and how the transactions identifiers are used to keep track of how much of data source that has been processed. A concrete example of this would be a Kafka topic or an append blob. Note: both the code and the transaction log entries have been simplified for brevity.
We have already used KDI directly for other data sources, streaming Corelight data from event hubs via Azure Container Apps. This reduced our costs by 90% while maintaining reliability through simple autoscaling based on CPU utilization.
However, Microsoft Defender for XDR presents a different challenge. As mentioned earlier, when Microsoft exports data to an event hub, different event types are mixed together in the same topic within a nested properties column. This structure does not align well with KDI’s 1:1 topic-to-table pattern. We would still need an intermediate bronze layer partitioned by category, followed by separate streaming jobs for each category - reintroducing the complexity we aimed to avoid.
This led us to examine Microsoft’s second export option: append blobs.
Append Blobs
Microsoft’s append blob export provides cleaner data structure. Each event type goes to a separate container: insights-logs-advancedhunting-{event_name}.
Microsoft creates new append blobs hourly with hierarchical paths: tenantId={guid}/y={year}/m={month}/d={day}/h={hour}/m=00/PT1H.json. Throughout each hour, data blocks are appended approximately every minute.
An append blob is optimized for append operations. Each block can be up to 4 MiB, and an append blob can include up to 50,000 blocks. Maximum size is slightly more than 195 GiB.
Understanding append blobs
Here is how Defender for XDR uses append blobs. Each event type is sent to a
separate container following the naming convention:
insights-logs-advancedhunting-{event_name}. For example, process creation events would go to
insights-logs-advancedhunting-DeviceProcessEvents.
Within each container, Microsoft creates a new append blob every hour using a
hierarchical folder structure organized by tenant ID and timestamp. The path
follows the pattern:
tenantId=<tenant_id>/y=2025/m=04/d=15/h=14/m=00/PT1H.json, where each line is
a JSON object.
Throughout each hour, Microsoft appends additional data blocks to that blob approximately every minute. When the blob reaches either its maximum size or block limit, it rolls over to a new file within the same hourly folder. At the start of each new hour, a fresh folder is created and the process repeats. This streaming pattern requires complex monitoring and state management, as illustrated by cloud-native solutions like Sumo Logic’s architecture.
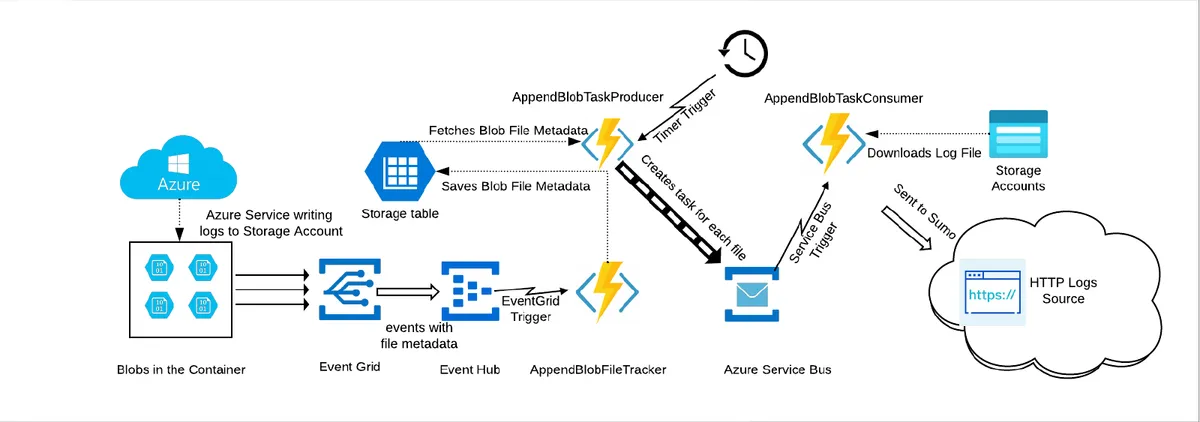
Fig 4: Sumo Logic’s architecture for processing append blobs requires a complex pipeline with Event Grid, Event Hubs, three separate Azure Functions, Service Bus queues, and multiple storage accounts - illustrating the operational complexity that traditional cloud-native solutions introduce for what is essentially a file monitoring and processing task.
Fundamentally, there are two main challenges that must be addressed when incrementally processing append blobs:
No notification mechanismThere are no other Event Grid events for appends blobs apart from the initial blob creation event. This requires us to implement our own blob monitoring solution.
State management complexityWe must track the processed offset for each blob to avoid reprocessing data - a problem that becomes increasingly difficult as the number of blobs grows.
A Serverless Processing Pipeline
Our solution uses a serverless architecture built on Azure Container App Jobs that takes advantage of Delta Lake’s transaction identifier mechanism. Rather than complex event-driven pipelines, we use scheduled jobs that discover files by listing blob storage directly, eliminating any dependency on Event Grid notifications.
The pipeline is built around Arrow and DuckDB to limit the copying of memory.
Each log event type is handled by a separate container app job that is
configured run runs X few minutes (with the value of X depending on the volume
for the particular event type), processing both the current hour and the
previous hour to ensure we capture events written near hour boundaries. For
example, a DeviceProcessEvents job running at 14:05 will scan both the 14:00
and 13:00 hour folders to ensure complete coverage.
For the state management, we use a combination of the date
and the filename for the transaction appId (e.g., 2025-06-11-22-PTH1.json), and store
the last processed byte offset in the version field.
When a job starts, it lists all blobs in the target containers using time-based
prefixes. For each blob it discovers, the job queries Delta Lake’s transaction
log to find the last processed byte offset. This gives us exactly-once
processing semantics - if we have never seen this blob before, then we start from offset 0. If we
have processed part of it, we resume exactly where we left off, without
requiring any external state storage.
Fig 5: Architectural overview of the serverless processing pipeline using Azure Container Apps. The jobs pull container images from Azure Container Registry, read JSON files from the source storage account containing Defender for XDR append blobs, and write transformed Delta tables to the destination storage account.
Rather than downloading entire blobs, we use Azure’s range request API to
download only the unprocessed portion. The job calculates remaining_bytes = blob_size - current_offset and downloads up to 1GB chunks directly into a Arrow
buffer or a memory mapped file. We also need to ensure that we do not process
partial JSON records that could cause parsing failures. This is done by scanning
backwards from the end of the chunk to find the last complete newline, and then
adjusting the processing offset accordingly.
The Arrow input stream that contains the JSON data is passed directly to DuckDB via
Ibis. The reason we use DuckDB for parsing is due to limitations with casting dynamic types
to string when
using the PyArrow read_json function with an explicit schema.
DuckDB parses the newline-delimited JSON with our pre-defined schema, then we apply lightweight transformations using Ibis expressions. This entire pipeline - from blob storage through transformations to Delta Lake - operates on the same memory buffer without creating temporary files or additional copies.
The code snippet below shows how everything works.
# download directly from blob into arrow buffer/memory map
buffer, updated_offset = (
download_blob_chunk(blob_client, current_offset, chunk_size)
)
# extract valid json records
jsonl_stream, updated_offset = (
validate_json_boundaries(pa.input_stream(buffer), updated_offset)
)
# use duckdb connection directtly we need to pass a file-like object
con.read_json(
jsonl_stream,
format="newline_delimited",
ignore_errors=True,
columns=from_pyarrow(schema),
).create(table_name)
# transform using duckdb operations via ibis
events = (
ibis.duckdb.from_connection(con)
.table(table_name)
.select(
_event_uuid=uuid(),
_ingested_at=_.time,
_processed_at=ibis.now(),
properties=_.properties
)
.unpack("properties")
.mutate(p_date=ibis.date(_.Timestamp))
)
# append events and attach an transaction identifier
events.to_delta(
table_uri,
mode="append",
commit_properties=CommitProperties(
app_transactions=[
Transaction(
app_id=app_id,
version=updated_offset,
)]
)
)The transformations add some metadata columns: id, ingestion timestamp and date
partitions for efficient querying. The unpack("properties") operation flattens
Defender for XDR’s nested JSON structure into table columns. Finally, we commit
the transformed data to Delta Lake with a transaction identifier that stores the
exact byte offset we have processed, enabling the next job run to resume
precisely where we left off.
This architecture eliminates the operational complexity shown in traditional cloud-native solutions. The combination of scheduled Container App jobs, Delta Lake’s transaction log, and zero-copy processing creates a cost-effective pipeline that scales effortlessly with data volume.
Fig 6: Sequence diagram illustrating the complete processing flow. The job queries Delta Lake for the last processed offset, downloads the unprocessed portion of the blob, performs internal transformations (JSON boundary validation, parsing, and schema application), then commits the transformed data along with the updated transaction identifier.
Cost Analysis
The serverless pipeline cut our infrastructure costs by 90%.
Initially, we configured the Azure Container App environment with both consumption and E4 workload profiles. Our intention was to use the consumption profile for low-volume event types and E4 for the high-volume ones. However, after looking at what resources we actually used, we found that the consumption profile alone was enough for our workloads.
Each job’s resources (CPU/memory) were configured based on empirical measurements during our testing phase. The key constraints we established were:
- Jobs were limited to downloading 1GB of data from Azure Blob Storage per run
- The frequency was determined from data volume - higher-volume sources run more often
- All jobs run at least once per hour
This time-based scheduling approach is simple to set up and manage, but it has limitations. A better approach would monitor blob metadata regularly and trigger Container App jobs only when new data arrives. However, this would require additional state management and coordination logic, reintroducing some of the complexity we aimed to avoid.
Compaction and optimizationIn addition to these regularly scheduled container app jobs, we had for each data source a companion job that ran at
midnight to perform compaction operations. These maintenance jobs use Delta Lake’s OPTIMIZE and VACUUM commands to
consolidate small files into larger ones and remove obsolete file versions, ensuring efficient storage utilization and
query performance as the tables grow over time.
Monthly cost
Fig 7: Cost comparison between processing Defender for XDR data using a Delta Live Tables streaming architecture versus a serverless approach built on scheduled Azure Container App jobs. The serverless solution reduces total infrastructure costs by 90%.
Moving from JVM-based distributed processing to native code for simple append operations delivered the cost reduction you would expect.
Issues and Limitations
Monitoring and observabilityWe have not covered monitoring in detail, but you will need comprehensive observability in production. OpenTelemetry, Azure Application Insights, or your preferred stack can track processing latencies, detect failures, and ensure data quality.
Error handling and dead letter queuingThe biggest issue we encountered is error handling for corrupt records. DuckDB’s JSON reader lacks the robust error handling available for CSV processing. Unlike the CSV reader, which can detect and store faulty records using reject tables, the JSON reader silently ignores completely invalid records. Corrupt or malformed JSON events disappear without notification.
This makes implementing dead letter queuing difficult - you cannot easily capture and route problematic records for manual inspection or reprocessing. For production security log processing this is a major limitation that requires additional validation steps and monitoring to detect data loss.
Summary
We described a serverless pipeline for ingesting Microsoft Defender for XDR security logs into Delta tables from append blobs.
For each event type, an Azure Container App job was configured to run on a schedule, reading data from hourly rotated append blobs. Delta Lake’s transaction identifier mechanism was used to keep track of how much of an append blob has been processed by storing the last processed byte offset in the transaction log.
Benchmarks showed a 90% reduction in infrastructure costs compared to our existing DLT and Azure Event Hubs based solution. This figure is consistent with others’ experiences moving from JVM-based distributed processing to native code for simple append operations.
The approach eliminates the operational complexity of streaming architectures by using scheduled batch processing. However, production deployments should address the error handling limitations we identified, particularly around corrupt record detection and DuckDB’s lack a dead letter queuing mechanism when parsing JSON files. For high-throughput streaming scenarios, consider the more recent alternative implementations by KyJah Keys and Raki Rahman referenced below.
References and related work
Additional resources:
-
Revolutionizing Delta Lake workflows on AWS Lambda with Polars, DuckDB, Daft & Rust by Daniel Beach. Has a section about using Lambda functions to process new CSV files from S3 and append the entries into one or more Delta tables. Daniel Beach frequently publishes insightful videos and blog posts on related topics.
-
Fast, Cheap and Easy Data Ingestion with AWS Lambda and Delta Lake by R Tyler Croy, Buoyant Data. Delta-rs, Lambda functions, Python and oxbow
-
Data Ingestion: Introducing delta-dotnet for Delta Lake by KyJah Keys and Raki Rahman and the blog post by Rakman. Goes through the issues of using KDI with Azure Event Hubs. It describes how to build an alternative application using the Delta lake bindings for C#.
-
Build more climate-friendly data applications with Rust by R Tyler Croy, Buoyant Data - Details a real-world case study where redesigning a Delta lake data ingestion pipeline to not use Kafka achieved a 99% cost reduction.